

In recent months, the term “RAG” (short for “Retrieval Augmented Generation”) has spread rapidly in connection with the creation of chatbots and AI assistants. In this blog post we describe:
- How RAG works
- Why the method actually represents a breakthrough
- What limits are currently still set for RAG
Generative AI cannot be used in companies without RAG
After the release of ChatGPT just over a year ago, it quickly became clear that Large Language Models (LLMs) like ChatGPT have limited knowledge from their training data and tend to embellish their statements and even make up information. They are said to have a tendency to “hallucinate”. For this reason, LLMs in their raw form are not suitable for applications in which the correctness of information or formulations in a specifically desired sense are important. To put it quite simply:
“ChatGPT alone is not suitable for use in companies.”
But what if you can get an LLM to rely on up-to-date and curated information to answer questions? As a company, you primarily want to use the language understanding and expression capabilities of generative AI, but you want to provide the knowledge base yourself. This is precisely the principle of Retrieval Augmented Generation, or RAG for short. It is a method that was first mentioned in 2020 in a paper entitled “Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks” (Lewis et al.) and has quickly become the new standard for information processing in companies.
How does RAG work?
As the name suggests, RAG works in two steps: Information search (retrieval) and answer generation.
- To answer a user query, the system first searches for relevant information. These can come from various sources, e.g. from websites, scientific articles or databases.
- The model then uses this retrieved information to generate a precise and contextualized response.
The following illustration shows the principle.
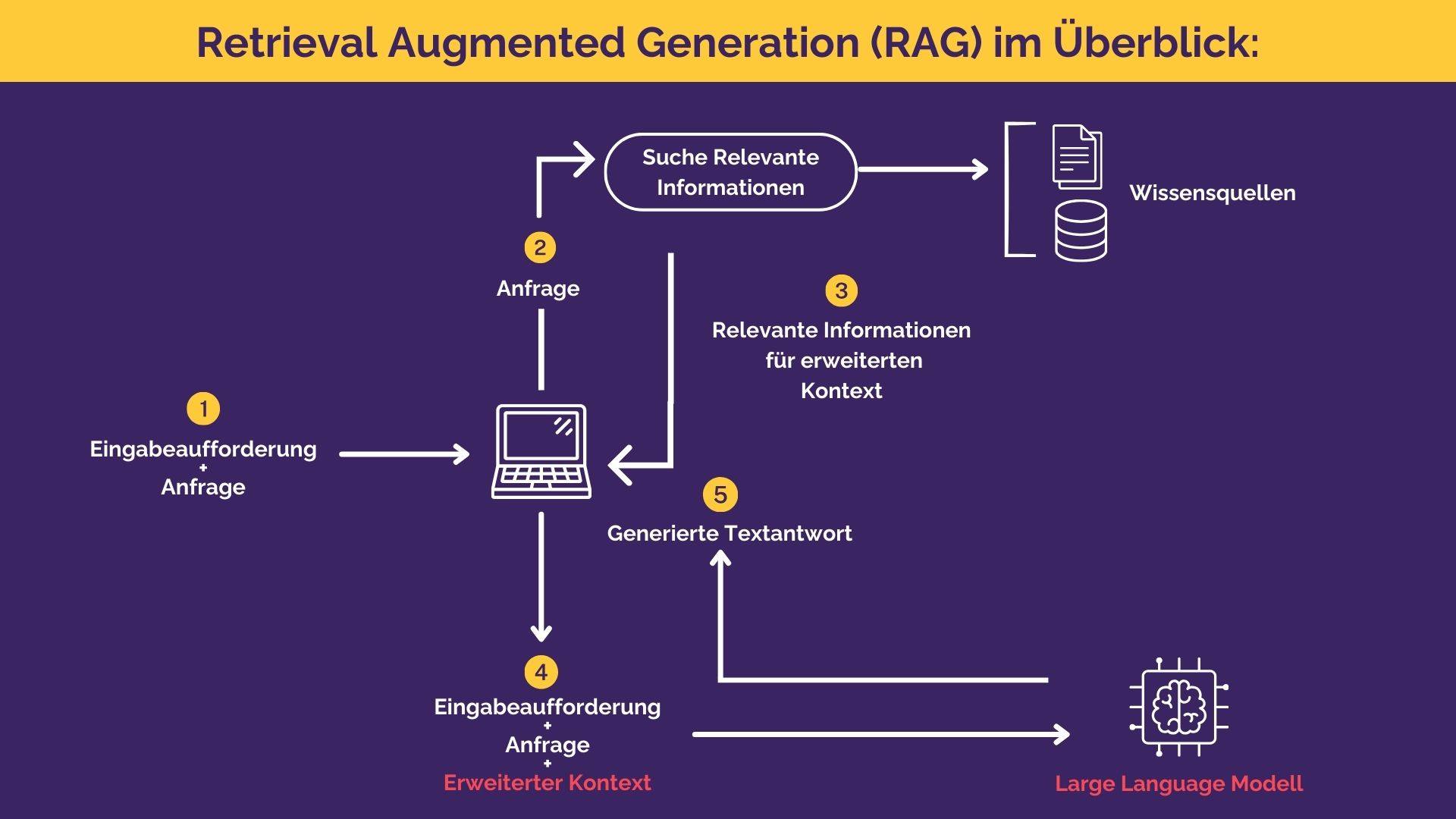
Better chatbots: use of LLMs and RAGs in combination
The use of RAG has several advantages over the use of LLMs without a retrieval component:
- RAG improves the accuracy and reliability of chatbot responses By providing specific information about a query, it reduces the likelihood of irrelevant or incorrect answers.
- It allows the answers to be much more up-to-date. By retrieving current information, RAG can respond to events or content that only occurred after the model was last trained.
- RAG promotes efficient use of information as it directly accesses an extensive data source rather than relying solely on what is already available in the model.
Due to these advantages, RAG has quickly established itself as a key technology for the use of chatbots in the corporate context.
The current limitations of RAG
Despite these advantages, developing a chatbot using the RAG methodology is no walk in the park. On the one hand, the quality and timeliness of the databases from which information is retrieved play a major role in the quality of the answers. Outdated or inaccurate data can lead to misleading answers. The old principle of data processing “garbage in, garbage out” also applies here. On the other hand, the retrieval step plays an almost more important role in this process than the generation step. If the right information is not found in the first step, no good answer can be generated in the second step. This means that the optimization of information searches continues to play an important role in the development of chatbots or AI assistants. At Kauz, we have responded to these challenges by further optimizing the RAG methodology on the one hand and supplementing it with classic rule-based NLU on the other. We will look at the associated challenges and possible solutions in the second part of this series of articles.
RAG is a breakthrough, but not a self-supporter
RAG marks a breakthrough in the development of chatbots and artificial intelligence. By skillfully combining information search and generation, RAG enables the creation of high-quality systems in a short time. Nevertheless, classic tasks such as selection and maintenance of the knowledge base, optimization of search algorithms and, if necessary, the use of the search engine are still being performed. annotation of data are not completely superfluous, but make the difference between a mediocre and a really good system.